遅延評価
概要
SX-Aurora TSUBASAは、PCI Expressに直接接続されているx86ノード(VH)とVector Engine(VE)で構成されています。VHとVE間のデータ転送がPythonスクリプトに頻繁に現れると、そのパフォーマンスは大幅に低下します。言い換えると、VHとVEの間のオーバーヘッドは、Pythonスクリプトの実行を高速化するための非常に重要な問題です。その解決策として、NLCPyはPythonスクリプトを遅延評価して、VEへの計算のリクエストをまとめて転送します。これにより、リクエストをオフロードする回数を減らすことができます。
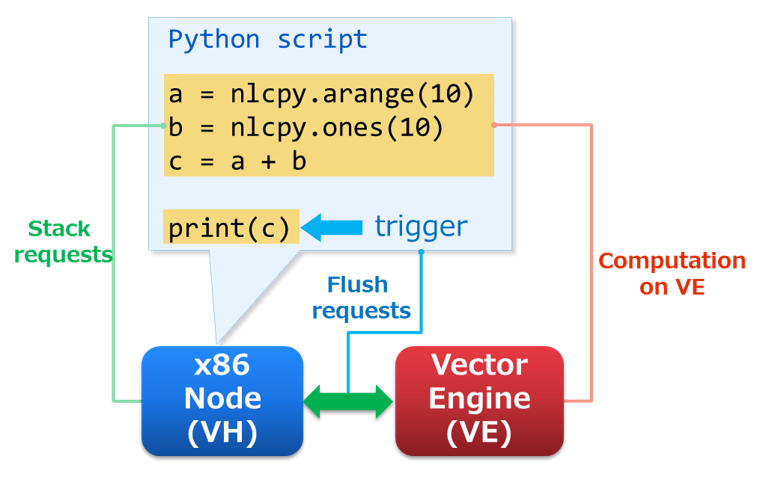
評価順序は以下のとおりです。
VHでリクエストをスタックします。
Pythonスクリプトにトリガーが表示されたら、リクエストをVEに掃き出します。
リクエストに基づいてVEで計算を開始し、計算が完了するまで待機します。
リクエスト管理
上述のリクエストは、NLCPyの関数の中で自動的にVEにフラッシュされ(掃き出され)、VE上で実行されます。フラッシュを引き起こすトリガーは以下の通りです。
- VE上の配列データがVH上で必要とされた場合
(例)
nlcpy.ndarrayを表示(print)、nlcpy.ndarray.get()の呼び出し、if/elifの条件文中にnlcpy.ndarrayを使用 - VHにスタックされたリクエストの数が100を超えた場合
- Pythonスクリプトが遅延評価に対応していない関数を呼び出した場合
(例)
nlcpy.fft.fft()やnlcpy.linalg.solve()等
nlcpy.request.flush() は、リクエストを意図的にフラッシュすることができます。また、nlcpy.request.set_offload_timing_onthefly() を呼び出すと、後続のリクエストは一関数ごとに実行されます。リクエストを管理する方法の詳細は、nlcpy.request をご参照ください。
デバッグのヒント
遅延評価を使用する場合、Pythonスクリプトが発生する警告の位置が正確でない可能性があります。したがって、警告の正確な位置を知りたい場合は、 nlcpy.request.set_offload_timing_onthefly() を使用してください。
遅延評価の警告例
# sample.py import nlcpy as vp a = vp.divide(1, 0) # divide by zero warning b = a + 1 print(b)
$ python sample.py sample.py:5: RuntimeWarning: divide by zero encountered in nlcpy.core.core print(b) inf
逐次評価の警告例
# sample.py import nlcpy as vp vp.request.set_offload_timing_onthefly() a = vp.divide(1, 0) # divide by zero warning b = a + 1 print(b)
$ python sample.py sample.py:4: RuntimeWarning: divide by zero encountered in nlcpy.core.core a = vp.divide(1, 0) # divide by zero warning inf
逐次評価と遅延評価の性能比較
ここでは、逐次評価( set_offload_timing_onthefly )と遅延評価 ( set_offload_timing_lazy )の簡単な性能比較を示します。
この場合、 遅延評価を使用すると、性能は約2倍向上します。
サンプルプログラム
# comparison.py import nlcpy as vp import time N = 10000 timings = [ vp.request.set_offload_timing_onthefly, vp.request.set_offload_timing_lazy, ] for t in timings: t() # set offload timing print(vp.request.get_offload_timing()) x = vp.zeros(N, dtype='i8') vp.request.flush() begin = time.time() for i in range(N): x[i] += i vp.request.flush() end = time.time() print(x) print("elapsed time =", end - begin, "\n")
実行結果
$ python comparison.py current offload timing is 'on-the-fly' [ 0 1 2 ... 9997 9998 9999] elapsed time = 1.168030023574829 current offload timing is 'lazy' [ 0 1 2 ... 9997 9998 9999] elapsed time = 0.5217337608337402